ASCII: Расшифровка аббревиатуры, история и применение
- Виды кодировок символов - набор символов (character set, charset) и синонимы: кодовая страница, кодировка (encoding). Например Unicode, Windows-1251(CP1251), ASCII.
- Punycode DNS — стандартизированный метод преобразования последовательностей Unicode- символов в ACE- последовательности
ASCII (American Standard Code for Information Interchange — американский стандартный код для обмена информацией; по-американски произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски произносится также [а́ски] или [аски́]).
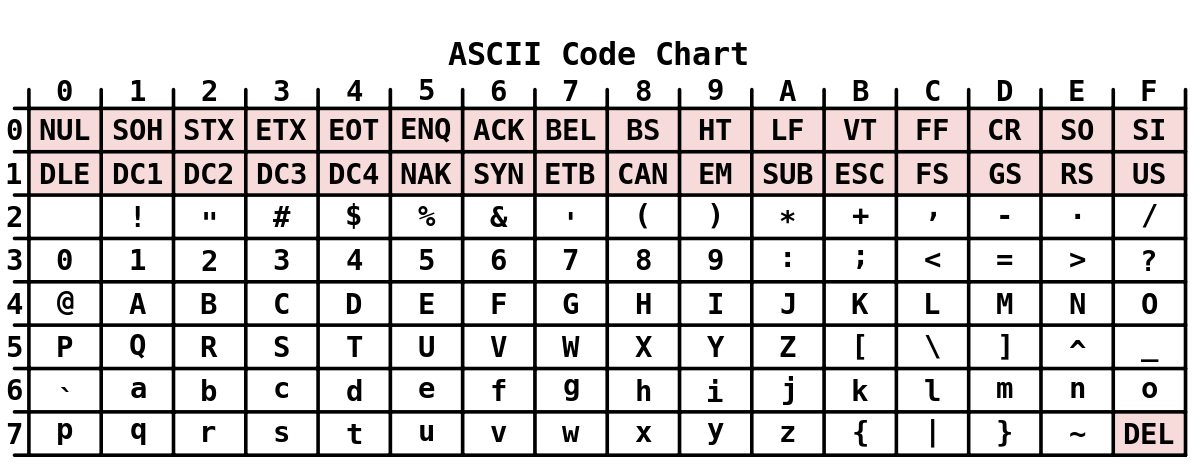
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованной второй половиной байта. Обычно символ ASCII расширяют до 8 бит, просто добавляя один нулевой бит в качестве старшего.
- NUL должен быть символом, где все биты установлены в 0.
- Коды десятичных цифр 0—9 должны идти в возрастающем порядке, причём коды двух соседних цифр должны отличаться на единицу.
Подробнее: Переносимый набор символов
Удобнее использовать 8-битные кодировки (кодовые страницы), где нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. В Юникоде (utf-8) первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
ASCII С++
Программа С++ отображает символы и их соответствующие символы из таблицы ASCII.
#include <stdlib.h>
#include <stdio.h>
/*Программа отображает символы и их соответствующие символы из таблицы ASCII.*/
int main() {
unsigned char a;
for (a=32;a<128;a++)
printf("%3d = '%c''\n",a,a);
return (EXIT_SUCCESS);
}
Важность кодировки ASCII, включающей латинский алфавит, цифры и основные знаки пунктуации, необычайно велика: почти все остальные (большие по размеру) кодировки совместимы с ней, т. е. размещают на своих первых 128 знакоместах те же самые символы в том же порядке.
Первые 32 позиции в кодировке ASCII заняты так называемыми управляющими символами (control characters), предназначенными не для передачи собственно текстовой информации, а для управления устройством, читающий (или получающим по линии связи) текстовый файл. Лишь немногие из этих символов — возврат каретки, перевод строки, табуляция — до сих пор используются в более-менее общепринятых значениях; остальные, давно уже вышедшие из употребления, в былые времена выполняли для «голого» ASCII-текста те же функции, которые сейчас возложены на разнообразные форматы данных и протоколы связи.
Задействовав в кодировке ASCII старший бит, мы получаем дополнительные 128 знакомест, которых должно хватить для кодирования, например, кириллического алфавита или набора каких-нибудь специальных символов. К сожалению, восьмибитных кодировок на свете существует гораздо больше, чем наборов символов, которые они кодируют. Очень характерна в этой связи ситуация с русским языком — анархия компьютеризации в нашей стране, наложившаяся на всемирную анархию конкурирующих компьютерных платформ и операционных систем, привела к тому, что для кириллицы существует сразу несколько однобайтовых кодовых таблиц.