Содержание
Руководство по iptables: Настройка и оптимизация фаервола Linux
iptables - утилита командной строки, является стандартным интерфейсом управления работой межсетевого экрана Netfilter для ядер Linux. При получении пакета, он передается Netfilter для принятия им решения: принять, обработать, или отбросить его на основе правил заданных с помощью iptables. Таким образом, iptables это все, что нужно для управления брандмауэром.
iptables может отслеживать состояние соединения и перенаправлять, изменять или отфильтровывать пакеты, основываясь не только на данных из их заголовков (источник, получатель) или содержимом пакетов, но и на основании данных о соединении. Такая возможность фаервола называется stateful-фильтрацией, в отличие от реализованной в ipchains примитивной stateless- фильтрации.
Примеры запуска iptables
Вывести все правила в iptables, возможны несколько вариантов:
iptables -S iptables -nL -v iptables -nL -v --line-number
- -v - задает расширенный вывод, включающий в себя счетчики пакетов и байт
- -х - показывать точные значения счетчиков
- -т - не делать обратного преобразования IP в DNS
- –line-numbers нумерует правила, зная номер можно удалить это правило
- -j используется для задания цели, например ACCEPT, ULOG, DROP и другие
- Опция -L определяет вывод статистики для цепочки (chain), если конкретная цепочка не задана, то для всех.
Ключ -D удалить правило по номеру, например:
iptables -nL -v --line-numbers | grep 10.9.0.4 4 0 0 DROP all 10.9.0.40 0.0.0.0/0 iptables -D FORWARD 4
Получить справочную информацию по любому из дополнительных критериев
iptables -m limit -h
Обнуление всех счетчиков в заданной цепочке. Если имя цепочки не указывается, то подразумеваются все цепочки. При использовании ключа -v совместно с командой -L, на вывод будут поданы и состояния счетчиков пакетов, попавших под действие каждого правила. Допускается совместное использование команд -L и -Z. В этом случае будет выдан сначала список правил со счетчиками, а затем произойдет обнуление счетчиков.
iptables -vL -Z INPUT
Отобразить все цепочки правил в NAT-таблице
iptables -t nat -L
Закрыть 80 порт и установить первым правилом
iptables -I INPUT 1 -p tcp --dport 80 -j DROP
Открыть все для ip 10.10.205.223 и установить первым правилом
iptables -I INPUT 1 -s 10.10.205.223 -j ACCEPT
- Очистить все правила iptables и задать по умолчанию:
iptables -F iptables -P INPUT ACCEPT iptables -P FORWARD ACCEPT iptables -P OUTPUT ACCEPT
Как сохранять и восстанавливать правила iptables
iptables-apply - перезагружает правила из конфига (/etc/network/iptables) iptables-restore - считывает правила из указаного файла iptables-save - сохраняет в указаный файл.
Утилиты netfilter/iptables.
 nfnetlink -интерфейс, позволяющий различным userspace-приложениям взаимодействовать с netfilter и conntrack.
nfnetlink -интерфейс, позволяющий различным userspace-приложениям взаимодействовать с netfilter и conntrack.
- iptstate — в какой-то мере аналог утилиты conntrack, хотя и не имеющий таких богатых возможностей. Предназначена для непрерывного вывода таблицы состояний соединений с периодическим обновлением, в стиле широко известной утилиты top. Поддерживает различные виды сортировки (по адресам/портам источника/назначения, тайм-ауту, счетчикам и т. п.). Позволяет удалять записи из таблицы состояний. Не поддерживает работу с таблицей ожидаемых (expected) соединений.
# aptitude install iptstate # iptstate -D 1720
- conntrack - инструмент, позволяющий системному администратору наблюдать таблицы состояний соединений и взаимодействовать с ними: очищать таблицы целиком, удалять отдельные записи, маркировать соединения вручную (аналог действия CONNMARK), устанавливать тайм-ауты соединений. Поддерживается фильтрация вывода (например, на основании адресов и/или портов источника и/или назначения), а также вывод в различных форматах, включая XML. Кроме того, данная утилита позволяет отслеживать в реальном времени события системы conntrack, например, открытие новых соединений или изменение состояния существующих.
# aptitude install conntrack
- conntrackd демон, обеспечивающий синхронизацию таблиц состояний с другими хостами, например в случае кластера. Также conntrackd можно использовать просто для удаленного сбора статистики по соединениям.
- l7-filter-userspace — демон, позволяющий определить протокол 7-го (прикладного) уровня модели OSI, которому принадлежит полученный пакет, на основании анализа его содержимого при помощи регулярных выражений. Результат анализа возвращает в маркировке пакета. Полезен при фильтрации и шейпинге трафика протоколов, не имеющих фиксированных номеров портов для соединений данных, например, BitTorrent. Впрочем, в настоящее время существуют и альтернативные решения — P2P-протоколы можно выделять при помощи критерия ipp2p (из набора xtables-addons), а вспомогательные соединения в известных системе conntrack протоколах (Раздел FTP: Протокол FTP, серверы, клиенты FTP для Linux и Windows, IRC, Что такое SIP протокол: принцип работы, адресация и методы) можно выделять при помощи критерия helper и маркировки соединений.
Ссылки на инструменты для управления netfilter/iptables.
- The netfilter.org "iptables" project - вся самая последняя информация
Инструменты для управления netfilter/iptables. Есть множество инструментов помогающие вам в настройке брандмауэра без знания iptables.
- Shorewall или более точно Shoreline Firewall — инструмент для настройки файрвола в Linux, обвязка к старому доброму iptables для обеспечения упрощённых методов конфигурирования.
- firestarter
- fwbuilder
- Arno-iptables-firewall это скрипт для настройки сетевого экрана (брандмауэра) как для одной так и для нескольких подсетей с поддержкой DSL/ADSL.
Архитектура netfilter/iptables
В системе Netfilter, пакеты пропускаются через цепочки. Цепочка является упорядоченным списком правил, а каждое правило может содержать критерии и действие или переход. Когда пакет проходит через цепочку, система netfilter по очереди проверяет, соответствует ли пакет всем критериям очередного правила, и если так, то выполняет действие (если критериев в правиле нет, то действие выполняется для всех пакетов проходящих через правило). Вариантов возможных критериев очень много. Например, пакет соответствует критерию –source 192.168.1.1 если в заголовке пакета указано, что отправитель — 192.168.1.1. Самый простой тип перехода, –jump, просто пересылает пакет в начало другой цепочки. Также при помощи –jump можно указать действие. Например, команды
iptables -A INPUT --source 192.168.1.1 --jump ACCEPT iptables -A INPUT --jump other_chain
означают «добавить к концу цепочки INPUT следующие правила: пропустить пакеты из 192.168.1.1, а всё, что останется — отправить на анализ в цепочку other_chain».
- Синтаксис правил:
В общем виде правила записываются примерно так:
iptables [-t table] command [match] [target/jump]
Нигде не утверждается, что описание действия (target/jump) должно стоять последним в строке, однако, такая нотация более удобочитаема. Как бы то ни было, но чаще всего вам будет встречаться именно такой способ записи правил.
Если в правило не включается спецификатор [-t table], то по умолчанию предполагается использование таблицы filter, если же предполагается использование другой таблицы, то это требуется указать явно. Спецификатор таблицы так же можно указывать в любом месте строки правила, однако более или менее стандартом считается указание таблицы в начале правила.
Далее, непосредственно за именем таблицы, должна стоять команда. Если спецификатора таблицы нет, то команда всегда должна стоять первой. Команда определяет действие iptables, например: вставить правило, или добавить правило в конец цепочки, или удалить правило и т.п.
Раздел match задает критерии проверки, по которым определяется подпадает ли пакет под действие этого правила или нет. Здесь мы можем указать самые разные критерии – IP-адрес источника пакета или сети, IP-адрес места назначения,порт, протокол, сетевой интерфейс и т.д. Существует множество разнообразных критериев, но об этом – несколько позже.
И наконец target указывает, какое действие должно быть выполнено при условии выполнения критериев в правиле. Здесь можно заставить ядро передать пакет в другую цепочку правил, "сбросить" пакет и забыть про него, выдать на источник сообщение об ошибке и т.п.
- Для добавления правила в цепочку используется ключ -A
iptables -A INPUT правило
добавит правило в цепочку INPUT таблицы filter (по умолчанию). Для указания таблицы, в цепочку которой следует добавить правило, используйте ключ -t:
iptables -t nat -A INPUT правило
добавит правило в цепочку INPUT таблицы nat.
- Цель по умолчанию задается с помощью ключа -P:
iptables -P INPUT DROP
- Ключ -I вставляет новое правило в цепочку.
iptables -I INPUT 1 -p tcp --dport 80 -j ACCEPT
Число, следующее за именем цепочки указывает номер правила, перед которым нужно вставить новое правило, другими словами число задает номер для вставляемого правила. В примере выше, указывается, что данное правило должно быть 1-м в цепочке INPUT.
Ключевые понятия iptables
Ключевыми понятиями iptables являются:
- Критерий — логическое выражение, анализирующее свойства пакета и/или соединения и определяющее, подпадает ли данный конкретный пакет под действие текущего правила. Критерий может быть общим, неявным и явным.
- Действие(цель) — описание действия, которое нужно проделать с пакетом и/или соединением в том случае, если они подпадают под действие этого правила. Стандартные действия доступные во всех цепочках:
- ACCEPT - пропустить, передать на обработку следующему правилу;
- DROP - удалить, больше над пакетом никакой обработки не производится;
- QUEUE - передать на анализ внешней программе;
- RETURN - вернуть на анализ в предыдущую цепочку
- REJECT - пакет отклоняется. В отличие от DROP, где пакет просто отбрасывается, в данном случае отправителю будет отправлено ICMP протокол диагностики перегрузки сети- сообщение "Port unreachable" («Порт недоступен»). С помощью опции –iptables что использовать reject или drop для блокировки можно изменить тип ICMP сообщения. Цель REJECT может быть использована только с цепочками INPUT, OUTPUT и FORWARD.
- Счетчик — компонент правила, обеспечивающий учет количества пакетов, которые попали под критерий данного правила. Также счетчик учитывает суммарный объем таких пакетов в байтах.
- Правило — состоит из критерия, действия и счетчика. Если пакет соответствует критерию, к нему применяется действие, и он учитывается счетчиком. Критерия может и не быть — тогда неявно предполагается критерий «все пакеты». Указывать действие тоже не обязательно — в отсутствие действия правило будет работать только как счетчик.
- Цепочка — упорядоченная последовательность правил. Цепочки можно разделить на пользовательские и базовые.
- Базовая цепочка — цепочка, создаваемая по умолчанию при инициализации таблицы. Каждый пакет, в зависимости от того, предназначен ли он самому хосту, сгенерирован им или является транзитным, должен пройти положенный ему набор базовых цепочек различных таблиц. Кроме того, базовая цепочка отличается от пользовательской наличием «действия по умолчанию» (default policy). Это действие применяется к тем пакетам, которые не были обработаны другими правилами этой цепочки и вызванных из нее цепочек. Имена базовых цепочек всегда записываются в верхнем регистре (PREROUTING, INPUT, FORWARD, OUTPUT, POSTROUTING).
- Пользовательская цепочка — цепочка, созданная пользователем. Может использоваться только в пределах своей таблицы. Рекомендуется не использовать для таких цепочек имена в верхнем регистре, чтобы избежать путаницы с базовыми цепочками и встроенными действиями.
- Таблица — совокупность базовых и пользовательских цепочек, объединенных общим функциональным назначением. Имена таблиц (как и модулей критериев) записываются в нижнем регистре, так как в принципе не могут конфликтовать с именами пользовательских цепочек. При вызове команды iptables таблица указывается в формате -t имя_таблицы. При отсутствии явного указания, используется таблица filter. Более подробно таблицы будут рассмотрены ниже.
Критерии
- Общие критерии - не зависят от типа протокола и не требуют загрузки специального модуля.
- -p, –protocol -критерий для определения типа протокола.
- [!] -s, –src, –source адрес[/маска][,адрес[/маска]…] - IP-адрес(а) источника пакета. Адрес источника может указываться так, как показано в примере, тогда подразумевается единственный IP-адрес. А можно указать адрес в виде address/mask, например как 192.168.0.0/255.255.255.0, или более современным способом 192.168.0.0/24, т.е. фактически определяя диапазон адресов Как и ранее, символ !, установленный перед адресом, означает логическое отрицание, т.е. –source ! 192.168.0.0/24 означает любой адрес кроме адресов 192.168.0.x. Начиная с версии iptables 1.4.6, в одном параметре -s можно указывать более одного адреса, разделяя адреса запятой. При этом для каждого адреса будет добавлено отдельное правило.
- -d, –dst, –destination IP-адрес(а) получателя. Имеет синтаксис схожий с критерием –source, за исключением того, что подразумевает адрес места назначения. Символ ! используется для логической инверсии критерия.
- [!] -i, –in-interface имя_интерфейса Определяет входящий сетевой интерфейс. Если указанное имя интерфейса заканчивается знаком «+» (например, tun+), то критерию соответствуют все интерфейсы, чьи названия начинаются на указанное имя (для нашего примера tun0, tun1, …). Данный критерий можно использовать в цепочках PREROUTING, INPUT и FORWARD.
- [!] -o, –out-interface имя_интерфейса Определяет исходящий сетевой интерфейс. Синтаксис аналогичен -i. Критерий можно использовать в цепочках FORWARD, OUTPUT и POSTROUTING.
- -f, –fragment - Правило распространяется на все фрагменты фрагментированного пакета, кроме первого, сделано это потому, что нет возможности определить исходящий/входящий порт для фрагмента пакета, а для ICMP-пакетов определить их тип. С помощью фрагментированных пакетов могут производиться атаки на ваш брандмауэр, так как фрагменты пакетов могут не отлавливаться другими правилами. Как и раньше, допускается использования символа ! для инверсии результата сравнения. только в данном случае символ ! должен предшествовать критерию -f, например ! -f. Инверсия критерия трактуется как "все первые фрагменты фрагментированных пакетов и/или нефрагментированные пакеты, но не вторые и последующие фрагменты фрагментированных пакетов".
- addrtype — позволяет проверить тип адреса источника и/или назначения с точки зрения подсистемы маршрутизации сетевого стека ядра. Допустимые типы адресов: UNSPEC (адрес 0.0.0.0), UNICAST, LOCAL (адрес принадлежит нашему хосту), BROADCAST, ANYCAST, MULTICAST, BLACKHOLE, UNREACHABLE, PROHIBIT, THROW, NAT, XRESOLVE. Подробнее о большинстве перечисленных типов адресов и их использовании в Linux (точнее, в подсистеме iproute2) можно почитать здесь. В качестве практического примера использования данного критерия можно привести простейшую защиту от спуфинга:
iptables -I INPUT -m addrtype --src-type LOCAL ! -i lo -j DROP
Это правило заблокирует пакеты, которые пришли с внешних интерфейсов, но при этом в качестве обратного адреса у них указан один из адресов, принадлежащих нашему хосту (например, 127.0.0.1).
- Неявные критерии - должен быть указан протокол (ключ -p).
-
- –sport, –source-port - Исходный порт, с которого был отправлен пакет. В качестве параметра может указываться номер порта или название сетевой службы. Соответствие имен сервисов и номеров портов вы сможете найти в файле /etc/services. При указании номеров портов правила отрабатывают несколько быстрее. однако это менее удобно при разборе листингов скриптов. Если же вы собираетесь создавать значительные по объему наборы правил, скажем порядка нескольких сотен и более, то тут предпочтительнее использовать номера портов. Номера портов могут задаваться в виде интервала из минимального и максимального номеров, например –source-port 22:80. Если опускается минимальный порт, т.е. когда критерий записывается как –source-port :80, то в качестве начала диапазона принимается число 0. Если опускается максимальный порт, т.е. когда критерий записывается как –source-port 22:, то в качестве конца диапазона принимается число 65535. Допускается такая запись –source-port 80:22, в этом случае iptables поменяет числа 22 и 80 местами, т.е. подобного рода запись будет преобразована в –source-port 22:80. Как и раньше, символ ! используется для инверсии. Так критерий –source-port ! 22 подразумевает любой порт, кроме 22. Инверсия может применяться и к диапазону портов, например –source-port ! 22:80. За дополнительной информацией обращайтесь к описанию критерия multiport.
- –dport, –destination-port Порт или диапазон портов, на который адресован пакет. Аргументы задаются в том же формате, что и для –source-port.
- –tcp-flags Определяет маску и флаги tcp-пакета. В качестве аргументов критерия могут выступать флаги SYN, ACK, FIN, RST, URG, PSH, а так же зарезервированные идентификаторы ALL и NONE. ALL – значит ВСЕ флаги и NONE - НИ ОДИН флаг. Так, критерий –tcp-flags ALL NONE означает – "все флаги в пакете должны быть сброшены". Как и ранее, символ ! означает инверсию критерия Важно: имена флагов в каждом списке должны разделяться запятыми, пробелы служат для разделения списков. Пример:
iptables -p tcp --tcp-flags SYN,FIN,ACK SYN
Пакет считается удовлетворяющим критерию, если из перечисленных флагов в первом списке в единичное состояние установлены флаги из второго списка. Так для вышеуказанного примера под критерий подпадают пакеты у которых флаг SYN установлен, а флаги FIN и ACK сброшены. Возможные флаги: SYN ACK FIN RST URG PSH. Также можно использовать псевдофлаги ALL и NONE, обозначающие «все флаги» и «ни одного флага» соответственно. Пример:
iptables -I INPUT -m conntrack --ctstate NEW,INVALID -p tcp --tcp-flags SYN,ACK SYN,ACK -j REJECT --reject-with tcp-reset
будет препятствовать спуфингу от нашего имени. Ведь если мы получаем пакет с установленными флагами SYN и ACK (такой комбинацией флагов обладает только ответ на SYN-пакет) по еще не открытому соединению, это означает, что кто-то послал другому хосту SYN-пакет от нашего имени, и ответ пришел к нам. Конечно, злоумышленнику предстоит еще угадать номер последовательности, но лучше не предоставлять ему такого шанса. Согласно приведенному правилу, наш хост ответит RST -пакетом, после получения которого атакуемый хост закроет соединение. Добавление такого правила в конфигурацию фаервола настоятельно рекомендуется, потому что если злоумышленнику удастся осуществить спуфинг-атаку от вашего имени, при расследовании этого эпизода следы приведут к вам.
- –syn
- –tcp-option
- Для -p UDP: Получение UDP пакетов не требует какого либо подтверждения со стороны получателя. Если они потеряны, то они просто потеряны (не вызывая передачу ICMP протокол диагностики перегрузки сети сообщения об ошибке).
- –sport, –source-port
- –dport, –destination-port
-
- –icmp-type
- Для -p sctp:
- –sport, –dport, –chunk-types
- Для -p DCCP:
- –sport, –dport, –dccp-types
-
Явные критерии
Перед использованием этих расширений, они должны быть загружены явно, с помощью ключа -m или –match.
Критерий Comment
Критерий Comment позволяет создавать подписи к правилам, например
iptables -A INPUT -m conntrack --ctstate INVALID -m comment --comment "запрет Invalid пакетов" -j DROP
Критерий Limit
Критерий limit должен подгружаться явно ключом -m limit. Прекрасно подходит для правил, производящих запись в системный журнал (logging) и т.п.
limit — позволяет ограничить количество пакетов в единицу времени. Параметры:
- –limit количество[/second|/minute|/hour|/day] — задает ограничение на количество пакетов в секунду (second), минуту (minute), час (hour) или сутки (day). Пакеты в пределах этого количества считаются удовлетворяющими критерию, сверх этого количества — не удовлетворяющими.
- –limit-burst количество — задает длину очереди, то есть максимальную пропускную способность.
Критерий -limit использует модель «дырявого ведра», и –limit-burst задает «объем ведра», а –limit — «скорость вытекания». Каждому такому критерию соответствует своя очередь, длина которой задается параметром –limit-burst. Если в очереди есть пакеты, то со скоростью, заданной в –limit, они покидают очередь и считаются удовлетворяющими критерию. Если же вся очередь занята, то новые пакеты в ней не регистрируются и считаются не удовлетворяющими критерию. Например,
iptables -I INPUT -m limit --limit 3/min --limit-burst 5 -j LOG --log-level DEBUG --log-prefix "INPUT packet: "
предполагает очередь на пять пакетов, которая «продвигается» со скоростью 3 пакета в минуту. При непрерывном поступлении входящих пакетов, очередь всегда будет заполнена, и в лог будут заноситься в среднем по три пакета в минуту. Однако, если входящих пакетов долго не будет, то очередь успеет очиститься, и при поступлении пяти и менее новых пакетов, они пойдут в лог подряд. В любом случае, скорость попадания пакетов в лог остается неизменной.
Типичная ошибка новичков — использовать limit для ограничения TCP-трафика, например, так:
iptables -A INPUT -p tcp --dport 80 -m limit --limit 10000/sec --limit-burst 10000 -j ACCEPT iptables -P INPUT DROP
Это пример попытки защитить web-сервер от DDoS-атаки, ограничив количество пакетов в единицу времени. Однако, это правило не помешает без особого труда завалить сервер запросами (считая, что на один запрос требуется два входящих пакета — SYN-пакет и пакеты данных, содержащий, например, только GET /, согласно спецификации HTTP 0.9). При этом могут возникнуть помехи для легальных пользователей, например, загружающих на сервер большой файл методом POST. Более корректным решением будет ограничивать не скорость входящего потока данных, а скорость открытия новых соединений:
iptables -A INPUT -p tcp --dport 80 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT iptables -A INPUT -p tcp --dport 80 -m conntrack --ctstate NEW -m limit --limit 32/sec --limit-burst 32 -j ACCEPT iptables -P INPUT DROP
Теперь мы ограничиваем количество не всех пакетов, а только новых, то есть мы разрешаем открывать не более 32 новых соединений в секунду. Впрочем, число 32 приведено здесь только для примера. Конкретное значение скорости для вашей задачи рекомендуем определять самостоятельно.
Критерий hashlimit
hashlimit — позволяет применять ограничения, аналогичные критерию limit, к группам хостов, подсетей или портов, используя всего одно правило. При этом для каждого хоста, подсети или порта создается отдельная очередь.
Критерий MAC
MAC -адрес (Ethernet Media Access Control) критерий используется для проверки исходного MAC- адреса пакета.
Модуль расширения должен подгружаться явно ключом -m mac.
Ключи:
- –mac-source - MAC адрес сетевого узла, передавшего пакет. MAC адрес должен указываться в форме XX:XX:XX:XX:XX:XX. Как и ранее, символ ! используется для инверсии критерия, например –mac-source ! 00:00:00:00:00:01, что означает - "пакет с любого узла, кроме узла, который имеет MAC адрес 00:00:00:00:00:01" . Этот критерий имеет смысл только в цепочках PREROUTING, FORWARD и INPUT.
iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01 -j DROP
Критерий Mark
Критерий mark предоставляет возможность "пометить" пакеты специальным образом. Mark - специальное поле, которое существует только в области памяти ядра и связано с конкретным пакетом. Может использоваться в самых разнообразных целях, например, ограничение трафика и фильтрация. На сегодняшний день существует единственная возможность установки метки на пакет в Linux – это использование действия MARK. Поле mark представляет собой беззнаковое целое число в диапазоне от 0 до 4294967296 для 32-битных систем.
- –mark
iptables -t mangle -A INPUT -m mark --mark 1
Критерий производит проверку пакетов, которые были предварительно "помечены". Метки устанавливаются действием MARK, которое мы будем рассматривать ниже. Все пакеты, проходящие через netfilter имеют специальное поле mark. Запомните, что нет никакой возможности передать состояние этого поля вместе с пакетом в сеть. Поле mark является целым беззнаковым, таким образом можно создать не более 4294967296 различных меток. Допускается использовать маску с меткам. В данном случае критерий будет выглядеть подобным образом: –mark 1/1. Если указывается маска, то выполняется логическое AND метки и маски.
маркируем пакет
iptables -t mangle -A PREROUTING -i eth0 -p tcp --dport 25 -j MARK --set-mark 888
далее при помощи утилит пакета Использование и примеры маршрутизации Linux2 пересылаем пакет в таблицу маршрутизации mytable
ip rule add fwmark 888 table mytable
Если указана маска, то перед сравнением с заданным значением маркировка каждого пакета комбинируется с этой маской посредством логической операции AND, то есть проверяется условие x & маска == значение (где x — маркировка текущего пакета). Такой подход позволит сравнивать значения отдельных бит. Например, критерию
-m mark --mark 64/64
будет отлавливать пакеты, в маркировке которых установлен 7-й бит (26 = 64, при этом первый бит соответствует 20). В частности, 64…127, 192…255, 320…383 и т. д. Еще один пример —
-m mark --mark 2/3
будет определять пакеты, в маркировке которых установлен второй бит, но снят первый. Такие числа будут нацело делиться на два, но не делиться на четыре — 2, 6, 10, 14, …
Критерий connmark
connmark — полностью аналогичен mark, но проверяет не маркировку пакета (nfmark), а маркировку соединения (ctmark). Также имеет параметр –mark с аналогичным синтаксисом.
Критерий connlimit
connlimit — позволяет ограничивать количество одновременно открытых соединений с каждого IP-адреса (или подсети).
# Разрешаем только одно одновременное соединение с одного айпи на smtp iptables -A FORWARD -p tcp --syn --dport smtp -m connlimit --connlimit-above 1 -j DROP # allow 2 telnet connections per client host iptables -p tcp --syn --dport 23 -m connlimit --connlimit-above 2 -j REJECT # you can also match the other way around: iptables -p tcp --syn --dport 23 -m connlimit ! --connlimit-above 2 -j ACCEPT # limit the nr of parallel http requests to 16 per class C sized # network (24 bit netmask) iptables -p tcp --syn --dport 80 -m connlimit --connlimit-above 16 \ --connlimit-mask 24 -j REJECT # Ставим ограничение на 5 соединений на 80 порт. iptables -A INPUT -p tcp --syn --dport 80 -m connlimit --connlimit-above 5 -j REJECT
Критерий recent
recent - это специальный критерий, позволяющий запоминать проходящие через него пакеты, а затем использовать полученную информацию для принятия решений. Recent запоминает не сами пакеты, а их количество, время поступления, адрес источника (в последних версиях iptables также может запоминать и адрес назначения), а также, при необходимости, TTL - Time to live.
# limit ssh-port connections per minute $IPT -I INPUT -p tcp --dport 22 -i $IFACE_EXT -m state --state NEW -m recent --set $IPT -I INPUT -p tcp --dport 22 -i $IFACE_EXT -m state --state NEW -m recent --update --seconds 60 --hitcount 2 -j DROP $IPT -A INPUT -p tcp -m tcp -i $IFACE_EXT --dport 22 -j ACCEPT
Критерий Multiport
Расширение multiport позволяет указывать в тексте правила несколько портов и диапазонов портов.
Вы не сможете использовать стандартную проверку портов и расширение -m multiport (например –sport 1024:63353 -m multiport –dport 21,23,80) одновременно. Подобные правила будут просто отвергаться iptables. Выделяет не один порт, как –dport или –sport, а несколько по списку (до 15 штук). Можно задавать диапазоны как первый_порт:последний_порт. Может быть использовано только вместе с -p udp или -p tcp.
- [!]–source-ports port1,port2,port3:port4
iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110
Служит для указания списка исходящих портов. С помощью данного критерия можно указать до 15 различных портов. Названия портов в списке должны отделяться друг от друга запятыми, пробелы в списке не допустимы. Данное расширение может использоваться только совместно с критериями -p tcp или -p udp. Главным образом используется как расширенная версия обычного критерия –source-port.
- [!]–destination-ports port1,port2,port3:port4
iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110 -j ACCEPT
Служит для указания списка входных портов. Формат задания аргументов полностью аналогичен -m multiport –source-port.
- [!]–ports port1,port2,port3:port4
iptables -A INPUT -p tcp -m multiport --port 22,53,80,110
Данный критерий проверяет как исходящий так и входящий порт пакета. Формат аргументов аналогичен критерию –source-port и –destination-port. Обратите внимание на то что данный критерий проверяет порты обеих направлений, т.е. если вы пишете -m multiport –port 80, то под данный критерий подпадают пакеты, идущие с порта 80 на порт 80.
Критерий iprange
iprange — позволяет указать диапазон IP-адресов, не являющийся подсетью. Поддерживает следующие параметры:
- [!] –src-range адрес[-адрес] — позволяет указать диапазон исходных адресов. Например,
iptables -I INPUT -m iprange --src-range 192.168.0.8-192.168.0.25 -j DROP
заблокирует все пакеты, исходный адрес которых лежит в диапазоне с 192.168.0.8 по 192.168.0.25 включительно.
- [!] –dst-range адрес[-адрес] — позволяет указать диапазон адресов назначения.
Критерий Owner
Расширение owner предназначено для проверки "владельца" пакета. Изначально данное расширение было написано как пример демонстрации возможностей iptables. Допускается использовать этот критерий только в цепочке OUTPUT. Такое ограничение наложено потому, что на сегодняшний день нет реального механизма передачи информации о "владельце" по сети. Справедливости ради следует отметить, что для некоторых пакетов невозможно определить "владельца" в этой цепочке. К такого рода пакетам относятся различные ICMP responses. Поэтому не следует применять этот критерий к ICMP responses пакетам.
Таблица ключи критерия Owner
Ключ --uid-owner Пример iptables -A OUTPUT -m owner --uid-owner 500 Описание Производится проверка "владельца" по User ID (UID). Подобного рода проверка может использоваться, к примеру, для блокировки выхода в Интернет отдельных пользователей. Ключ --gid-owner Пример iptables -A OUTPUT -m owner --gid-owner 0 Описание Производится проверка "владельца" пакета по Group ID (GID). Ключ --pid-owner Пример iptables -A OUTPUT -m owner --pid-owner 78 Описание Производится проверка "владельца" пакета по Process ID (PID). Этот критерий достаточно сложен в использовании, например, если мы хотим позволить передачу пакетов на HTTP порт только от заданного демона, то нам потребуется написать небольшой сценарий, который получает PID процесса (хотя бы через ps) и затем подставляет найденный PID в правила. Пример использования критерия можно найти в Pid-owner.txt. Ключ --sid-owner Пример iptables -A OUTPUT -m owner --sid-owner 100 Описание Производится проверка Session ID пакета. Значение SID наследуются дочерними процессами от "родителя", так, например, все процессы HTTPD имеют один и тот же SID (примером таких процессов могут служить HTTPD Apache и Roxen). Пример использования этого критерия можно найти в Sid-owner.txt. Этот сценарий можно запускать по времени для проверки наличия процесса HTTPD, и в случае отсутствия - перезапустить "упавший" процесс, после чего сбросить содержимое цепочки OUTPUT и ввести ее снова.
Критерий State
Идеологический предшественник критерия conntrack. Имеет единственный параметр –state, аналогичный параметру –ctstate критерия conntrack (но, в отличие от него, не поддерживающий состояния DNAT и SNAT). Долгое время был основным критерием определения состояния, и до сих пор фигурирует во многих руководствах и примерах. Однако в настоящее время разработчики iptables рекомендуют использовать вместо него критерий conntrack. Возможно, что критерий state вообще будет удален из будущих версий iptables/netfilter.
Критерий state используется совместно с кодом трассировки соединений и позволяет нам получать информацию о признаке состояния соединения, что позволяет судить о состоянии соединения, причем даже для таких протоколов как ICMP и UDP. Данное расширение необходимо загружать явно, с помощью ключа -m state. На сегодняшний день можно указывать 4 состояния: INVALID, ESTABLISHED, NEW и RELATED.
Ключ –state
Пример iptables -A INPUT -m state --state RELATED,ESTABLISHED
Разрешаем прохождение statefull-пакетов. Эта цепочка обязательная в любых настройках iptables, она разрешает прохождение пакетов в уже установленных соединениях(ESTABLISHED), и на установление новых соединений от уже установленных (RELATED).
Критерий TOS
Критерий TOS предназначен для проведения проверки битов поля TOS. TOS – Type Of Service – представляет собой 8-ми битовое, поле в заголовке IP-пакета. Модуль должен загружаться явно, ключом -m tos.
От переводчика: Далее приводится описание поля TOS, взятое не из оригинала, поскольку оригинальное описание я нахожу несколько туманным.
Данное поле служит для нужд маршрутизации пакета. Установка любого бита может привести к тому, что пакет будет обработан маршрутизатором не так как пакет со сброшенными битами TOS. Каждый бит поля TOS имеет свое значение. В пакете может быть установлен только один из битов этого поля, поэтому комбинации не допустимы. Каждый бит определяет тип сетевой службы:
Минимальная задержка Используется в ситуациях, когда время передачи пакета должно быть минимальным, т.е., если есть возможность, то маршрутизатор для такого пакета будет выбирать более скоростной канал. Например, если есть выбор между оптоволоконной линией и спутниковым каналом, то предпочтение будет отдано более скоростному оптоволокну.
Максимальная пропускная способность Указывает, что пакет должен быть переправлен через канал с максимальной пропускной способностью. Например спутниковые каналы, обладая большей задержкой имеют высокую пропускную способность.
Максимальная надежность Выбирается максимально надежный маршрут во избежание необходимости повторной передачи пакета. Примером могут служить PPP и SLIP соединения, которые по своей надежности уступают, к примеру, сетям X.25, поэтому, сетевой провайдер может предусмотреть специальный маршрут с повышенной надежностью.
Минимальные затраты Применяется в случаях, когда важно минимизировать затраты (в смысле деньги) на передачу данных. Например, при передаче через океан (на другой континент) аренда спутникового канала может оказаться дешевле, чем аренда оптоволоконного кабеля. Установка данного бита вполне может привести к тому, что пакет пойдет по более "дешевому" маршруту.
Обычный сервис В данной ситуации все биты поля TOS сброшены. Маршрутизация такого пакета полностью отдается на усмотрение провайдера.
Таблица 6-14. Ключи критерия TOS
Ключ –tos Пример iptables -A INPUT -p tcp -m tos –tos 0x16 Описание Данный критерий предназначен для проверки установленных битов TOS, которые описывались выше. Как правило поле используется для нужд маршрутизации, но вполне может быть использовано с целью "маркировки" пакетов для использования с iproute2 и дополнительной маршрутизации в linux. В качестве аргумента критерию может быть передано десятичное или шестнадцатиричное число, или мнемоническое описание бита, мнемоники и их числовое значение вы можете получить выполнив команду iptables -m tos -h. Ниже приводятся мнемоники и их значения. Minimize-Delay 16 (0x10) (Минимальная задержка), Maximize-Throughput 8 (0x08) (Максимальная пропускная способность), Maximize-Reliability 4 (0x04) (Максимальная надежность), Minimize-Cost 2 (0x02) (Минимальные затраты), Normal-Service 0 (0x00) (Обычный сервис)
Критерий TTL
TTL - Time to live (Time To Live) является числовым полем в IP заголовке. При прохождении очередного маршрутизатора, это число уменьшается на 1. Если число становится равным нулю, то отправителю пакета будет передано ICMP сообщение типа 11 с кодом 0 (TTL equals 0 during transit) или с кодом 1 (TTL equals 0 during reassembly) . Для использования этого критерия необходимо явно загружать модуль ключом -m ttl.
От переводчика: Опять обнаружилось некоторое несоответствие оригинального текста с действительностью, по крайней мере для iptables 1.2.6a, о которой собственно и идет речь, существует три различных критерия проверки поля TTL, это -m ttl –ttl-eq число, -m ttl –ttl-lt число и -m ttl –ttl-gt число. Назначение этих критериев понятно уже из их синтаксиса. Тем не менее, я все таки приведу перевод оригинала:
Ключи критерия TTL
Ключ –ttl Пример iptables -A OUTPUT -m ttl –ttl 60 Описание Производит проверку поля TTL на равенство заданному значению. Данный критерий может быть использован при наладке локальной сети, например: для случаев, когда какая либо машина локальной сети не может подключиться к серверу в Интернете, или для поиска "троянов" и пр. Вобщем, области применения этого поля ограничиваются только вашей фантазией. Еще один пример: использование этого критерия может быть направлено на поиск машин с некачественной реализацией стека TCP/IP или с ошибками в конфигурации ОС.
Критерий "мусора" (Unclean match)
Критерий unclean не имеет дополнительных ключей и для его использования достаточно явно загрузить модуль. Будьте осторожны, данный модуль находится еще на стадии разработки и поэтому в некоторых ситуациях может работать некорректно. Данная проверка производится для вычленения пакетов, которые имеют расхождения с принятыми стандартами, это могут быть пакеты с поврежденным заголовком или с неверной контрольной суммой и пр., однако использование этой проверки может привести к разрыву и вполне корректного соединения.
Действие
Действия могут быть терминальными и нетерминальными.
- Терминальными называются действия, которые прерывают прохождение пакета через текущую базовую цепочку. То есть если к пакету в рамках некоторого правила было применено терминальное действие, он уже не проверяется на соответствие всем следующим правилам в этой цепочке (и в тех цепочках, из которых она была вызвана, если это пользовательская цепочка). Терминальными являются все действия, специфичные для таблиц filter и nat. Терминальными являются ACCEPT, DROP, REJECT, NFQUEUE, QUEUE.
- Нетерминальными, соответственно, являются действия, не прерывающие процесс прохождения пакета через цепочки. Нетерминальными являются действия, специфичные для таблицы mangle, а из перечисленных выше — LOG, ULOG и NFLOG.
Цепочка. Таблица.
Существует пять типов стандартных цепочек, встроенных в систему:
- PREROUTING — для изначальной обработки входящих пакетов.
- INPUT — для входящих пакетов адресованных непосредственно локальному процессу (клиенту или серверу).
- FORWARD — для входящих пакетов перенаправленных на выход (заметьте, что перенаправляемые пакеты проходят сначала цепь PREROUTING, затем FORWARD и POSTROUTING).
- OUTPUT — для пакетов генерируемых локальными процессами.
- POSTROUTING — для окончательной обработки исходящих пакетов.
Также можно создавать и уничтожать собственные цепочки при помощи утилиты iptables.
Цепочки организованны в таблицы:
- raw — просматривается до передачи пакета системе определения состояний. Используется редко, например для маркировки пакетов, которые НЕ должны обрабатываться системой определения состояний. Для этого в правиле указывается действие NOTRACK. Содержит цепочки PREROUTING и OUTPUT.
- mangle — содержит правила модификации (обычно заголовка) IP‐пакетов. Среди прочего, поддерживает действия TTL, TOS, и MARK (для изменения полей TTL и TOS, и для изменения маркеров пакета). Редко необходима и может быть опасна. Содержит все пять стандартных цепочек:
- nat — просматривает только пакеты, создающие новое соединение (согласно системе определения состояний). Поддерживает действия DNAT, SNAT, MASQUERADE, REDIRECT. Содержит цепочки PREROUTING, OUTPUT, POSTROUTING.
- filter — основная таблица, используется по умолчанию если название таблицы не указано. Содержит цепочки: INPUT, FORWARD, OUTPUT.
- security - Предназначена для изменения маркировки безопасности (меток SELinux как правильно отключить!! Для начинающих) пакетов и соединений. Данная таблица добавлена в ядро Linux в версии 2.6.27. Ранее операции с метками безопасности выполнялись в таблице mangle, и в целях обратной совместимости все действия, разрешенные для таблицы security, можно использовать и в таблице mangle.
Цепочки с одинаковым названием но в разных таблицах — совершенно независимые объекты. Например, raw PREROUTING и mangle PREROUTING обычно содержат разный набор правил; пакеты сначала проходят через цепочку raw PREROUTING, а потом через mangle PREROUTING.
Обработка пакета
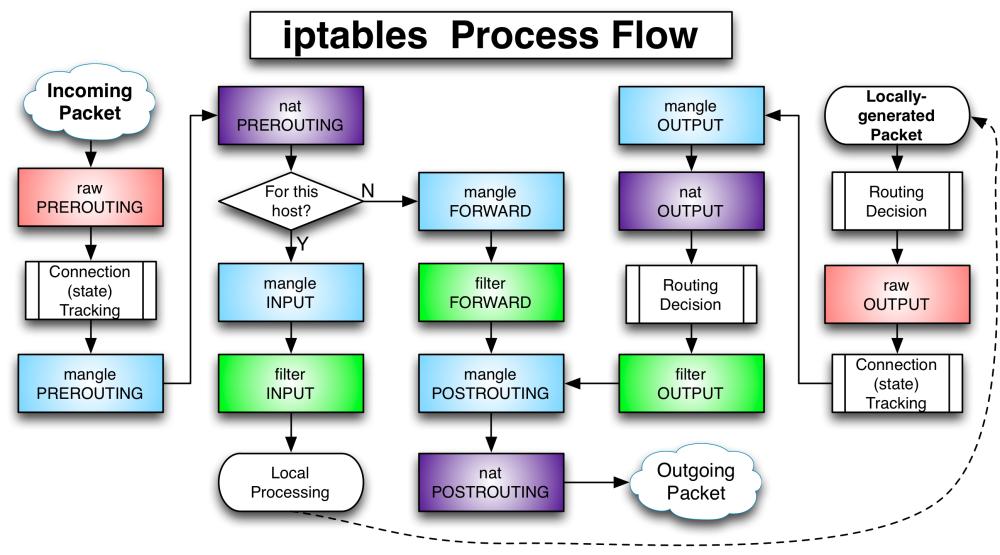
Схематично обработку пакета можно изобразить следующим образом:
PACKET IN --->---PREROUTING---[ маршрутизация ]--->----FORWARD---->---POSTROUTING--->--- PACKET OUT
- mangle | - mangle - mangle
- nat (dst) | - filter - nat (src)
| |
| |
INPUT OUTPUT
- mangle - mangle
- filter - nat (dst)
| - filter
| |
`---->----[ приложение ]---->----'
Входящий пакет начинает обрабатываться брандмауэром с цепочки PREROUTING в таблице mangle. Затем он обрабатывается правилами цепочки PREROUTING таблицы nat. На этом этапе проверяется, не требуется ли модификация назначения пакета (DNAT). Важно сменить назначение сейчас, потому что маршрут пакета определяется сразу после того, как он покинет цепочку PREROUTING. После этого он будет отправлен на цепочку INPUT (если целью пакета является этот компьютер) или FORWARD (если его целью является другой компьютер в сети).
Если целью пакета является другой компьютер, то пакет фильтруется правилами цепочки FORWARD таблиц mangle и filter, а затем к нему применяются правила цепочки POSTROUTING. На данном этапе можно использовать SNAT/MASQUARADE (подмена источника/маскировка). После этих действий пакет (если выжил) будет отправлен в сеть
Если назначением пакета является сам компьютер с брандмауэром, то, после маршрутизации, он обрабатывается правилами цепочек INPUT таблиц mangle и filter. В случае прохождения цепочек пакет передается приложению.
- mangle PREROUTING
- nat PREROUTING
- mangle INPUT
- filter INPUT
Когда приложение, на машине с брандмауэром, отвечает на запрос или отправляет собственный пакет, то он обрабатывается цепочкой OUTPUT таблицы filter. Затем к нему применяются правила цепочки OUTPUT таблицы nat, для определения, требуется-ли использовать DNAT (модификация назначения), пакет фильтруется цепочкой OUTPUT таблицы filter и выпускается в цепочку POSTROUTING которая может использовать SNAT и Что такое QoS. В случае успешного прохождения POSTROUTING пакет выходит в сеть.
- ??? какая правильна последовательность прохождения пакета на выходе?
- mangle OUTPUT
- nat OUTPUT
- filter OUTPUT
Немного о протоколе TCP/IP
Порты TCP. Что такое TCP / IP порт/IP является протоколом, в котором соединение устанавливается в 3 фазы. Если компьютер А пытается установить соединение с компьютером Б они обмениваются специальными TCP пакетами.
A: SYN пакет (првыед Б!) Б: ACK пакет, SYN пакет (Ога!, как оно?) A: ACK пакет (дык, ничего)
После чего соединение считается установленным (ESTABLISHED). iptables различает эти состояния как NEW и ESTABLISHED.
FIN (англ. final, бит) — флаг, будучи установлен, указывает на завершение соединения.
Механизм определения состояний
Компонент netfilter, обеспечивающий отслеживание состояния соединений и классификацию пакетов с точки зрения принадлежности к соединениям, что позволяет netfilter осуществлять полноценную stateful-фильтрацию трафика. Как и netfilter, система conntrack является частью ядра Linux. К ее задачам относятся:
- Отслеживание состояний отдельных соединений с тем, чтобы классифицировать каждый пакет либо как относящийся к уже установленному соединению, либо как открывающий новое соединение. При этом понятие состояние соединения искусственно вводится для протоколов, в которых оно изначально отсутствует (UDP, ICMP). При работе же с протоколами, поддерживающими состояния (например, TCP), conntrack активно использует эту возможность, тесно взаимодействуя с базовой сетевой подсистемой ядра Linux.
- Отслеживание связанных соединений, например, ICMP-ответов на TCP и UDP-пакеты. Более сложный вариант — протоколы, использующие несколько соединений в одной сессии, например, FTP. Для правильной обработки таких протоколов conntrack использует специальные модули (conntrack helpers), которые анализируют трафик и «выхватывают» информацию протокола о новых соединениях (например, порт, на который оно будет открыто), что позволяет обеспечить их корректную фильтрацию, маршрутизацию, шейпинг и пропускание через NAT.
Критерии состояния соединения
conntrack
Основной критерий, используемый для контроля состояния соединения. Он предоставляет эффективный набор инструментов, позволяющий использовать информацию системы conntrack о состоянии соединения.
- [!] –ctstate маска
Маска содержит перечисление через запятую список возможных состояний соединения. Пакет считается удовлетворяющим критерию, если соединение, по которому он проходит, находится в одном из перечисленных состояний. Возможные состояния:
- NEW — соединение не открыто, то есть пакет является первым в соединении.
- ESTABLISHED — пакет относится к уже установленному соединению. Обычно такие пакеты принимаются без дополнительной фильтрации, как и в случае с RELATED.
- RELATED — пакет открывает новое соединение, логически связанное с уже установленными, например, открытие канала данных в пассивном режиме FTP.
- INVALID — пакет по смыслу должен принадлежать уже установленному соединению (например, ICMP-сообщение port-unreachable), однако такое соединение в системе не зарегистрировано. Обычно к таким пакетам применяют действие DROP:
iptables -I INPUT -m conntrack --ctstate INVALID -j DROP
- UNTRACKED — отслеживание состояния соединения для данного пакета было отключено. Обычно оно отключается с помощью действия NOTRACK в таблице raw.
- DNAT — показывает, что к данному соединению применена операция подмены адреса назначения.
- SNAT — показывает, что к данному соединению применена операция подмены адреса источника.
iptables NAT
Описание технологии, задание размера таблиц смотреть в NAT преобразование сетевых адресов.
- SNAT (source NAT) - используется для реального IP
- DNAT - иcпользуется для проброса портов в паре с SNAT
- Маскарадинг (Masquerading) - NAT для динамического внешнего IP. Тип трансляции сетевого адреса, при которой адрес отправителя подставляется динамически, в зависимости от назначенного интерфейсу адреса.
# для постоянного IP (10.5.21.24) $IPT -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT --to-source 10.5.21.24:30000-50000 $IPT -t nat -A POSTROUTING -o eth0 -j SNAT --to-source 10.5.21.24 # для динамического IP $IPT -t nat -A POSTROUTING -o eth0 -j MASQUERADE # проброс порта 3389 $IPT -t nat -A PREROUTING -p tcp --dport 3389 -j DNAT \ --to-destination 172.16.23.24:3389
Проброс torrent UDP and TCP. На порт 51413 должен быть настроен клиент (например, Transmission).
$IPT -t nat -A PREROUTING -i $ISP_Valor -p tcp -m tcp --dport 51413 -j DNAT --to 10.26.95.251:51413 $IPT -A FORWARD -p tcp -m tcp -d 10.26.95.251 --dport 51413 -j ACCEPT $IPT -t nat -A PREROUTING -i $ISP_Valor -p udp -m udp --dport 51413 -j DNAT --to 10.26.95.251:51413 $IPT -A FORWARD -p udp -m udp -d 10.26.95.251 --dport 51413 -j ACCEPT
Маскарадинг в основе своей представляет то же самое, что и SNAT только не имеет ключа –to-source. Маскарадинг умеет работать с динамически получаемыми IP, например в случае когда провайдер выдает IP по Настройка DHCP сервера Linux, FreeBSD. Если у вас статическое IP подключение, то лучшим выходом будет использование SNAT.
Действие MASQUERADE допускается указывать только в цепочке POSTROUTING таблицы nat, так же как и действие SNAT. В цепочке PREROUTING мы будем менять информацию о получателе пакета (DNAT), а в цепочке POSTROUTING - об отправителе (SNAT).
iptables -t nat -A POSTROUTING -s 192.168.46.0/24 -o $IFACE_EXT1 -j MASQUERADE
Обязательно выставить значение в 1
# sysctl net.ipv4.ip_forward net.ipv4.ip_forward = 0
Этого можно добиться без перезагрузки ОС командой
# sysctl -w net.ipv4.ip_forward=1 net.ipv4.ip_forward = 1
и обязательно прописать(раскоментировать) строку net.ipv4.ip_forward = 1 в /etc/sysctl.conf
- Запрет NAT. Если нужно запретить какому-нибудь серому хосту хождение в Интернет по портам 80, 443, можно написать так:
$IPT -A FORWARD -p tcp -m multiport --port 80,443 -s 192.168.1.11 -j DROP
LOG: Протоколирование правил Iptables
Журналы брандмауэра имеют важное значение для обнаружения признаков «взлома», ошибок в написании правил и обнаружении необычного поведения вашей сети. Вам необходимо создать правила, чтобы эти события попадали в журнал, так же рекомендуется отслеживать в логах поведение создаваемых новых правил, а также рекомендуется протоколировать любые правила которые решают судьбу пакета (такие как ACCEPT, DROP, или REJECT).
- LOG — позволяет записывать информацию о пакетах в журнал ядра (Использование syslog).
Например, перед строкой
iptables -A INPUT -p tcp -m multiport --dports 22,53,8080,139,445 -j ACCEPT
мы добавим строку
iptables -A INPUT -p tcp -m multiport --dports 22,53,8080,139,445 -j LOG --log-level INFO --log-prefix "New connection from ours: "
то для каждого нового соединения к нашему хосту из нашей подсети в системном журнале будет появляться запись примерно такого вида:
Jul 16 20:10:40 interdictor kernel: New connection from ours: IN=eth0 OUT= MAC=00:15:17:4c:89:35:00:1d:60:2e:ed:a5:08:00 SRC=10.134.0.67 DST=10.134.0.65 LEN=48 TOS=0x00 PREC=0x00 TTL=112 ID=38914 DF PROTO=TCP SPT=31521 DPT=8080 WINDOW=65535 RES=0x00 SYN URGP=0
Такая запись содержит очень много полезной информации. Начинается она с даты и времени получения пакета. Затем идет имя нашего хоста (interdictor) и источник сообщения (для сообщений фаервола это всегда ядро). Потом идет заданный нами префикс (New connection from ours:), после чего следуют данные о самом пакете: входящий интерфейс (определен для цепочек PREROUTING, INPUT и FORWARD), исходящий интерфейс (определен для цепочек FORWARD, OUTPUT и POSTROUTING), далее — сцепленные вместе MAC-адреса источника и назначения (сначала идет адрес назначения, в данном случае это наш интерфейс eth1 с маком 00:15:17:4C:89:35, затем адрес источника, в нашем случае это 00:1D:60:2E:ED:A5, и в конце следует значение EtherType, 08:00 соответствует протоколу IPv4]), потом IP-адреса источника (10.134.0.67) и получателя (10.134.0.65, это наш хост), а затем идет различная техническая информация. Например, протокол (Порты TCP. Что такое TCP / IP порт), порты источника и назначения (31521 и 8080 соответственно), Байт TOS Тип обслуживания и TTL - Time to live, длина пакета (48 байт), наличие флага SYN и т. д.
Указав соответствующие параметры действия LOG, можно дополнить эту информацию номером Порты TCP. Что такое TCP / IP порт-последовательности (опция –log-tcp-sequence), выводом включенных опций протоколов TCP (опция –log-tcp-options) и IP (–log-ip-options), а также идентификатором пользователя, процесс которого отправил данный пакет (–log-uid, имеет смысл только в цепочках OUTPUT и POSTROUTING).
Параметр –log-prefix позволяет задать поясняющую надпись, упрощающую поиск сообщений в системных журналах. Параметр –log-level определяет уровень важности лог-сообщения, от которого зависит, в частности, в какой именно из журналов будет записано это сообщение. За более подробными сведениями обратитесь к документации по вашему демону системного лога.
Данная запись появится в журналах /var/log/messages, /var/log/syslog, и /var/log/kern.log. Это поведение можно изменить отредактировав файл настроек /etc/syslog.conf или установив и настроить демон ulogd и использовать ULOG вместо обычных журналов LOG. Демон ulogd является сервером пользовательского уровня, который «слушает» сообщения протоколирования событий получаемых от ядра, и может сохранять их в любой файл, или в базы данных PostgreSQL или MySQL. Для более легкого анализа содержимого журналов используйте инструмменты анализа, такие как fwanalog, fwlogwatch анализатор журналов брандмауэра, или Lire.
#Протоколирование цепочки по умолчанию -P $IPT -A INPUT -j LOG --log-level INFO --log-prefix "-P INPUT DROP: " $IPT -A INPUT -j DROP
При количестве пакетов больше 5, правило сработает один раз в секунду. Остальные попытки в log файл записываться не будут. Так можно уменьшить объем лог файла.
$IPT -A INPUT -i eth0 -m limit --limit-burst 5 --limit 1/s \ -j LOG --log-level debug --log-prefix "IN_ETH0" $IPT -A OUTPUT -o eth0 -m limit --limit-burst 5 --limit 1/s \ -j LOG --log-level debug --log-prefix "OUT_ETH0"
ULOG: Протоколирование правил Iptables
ULOG -демон ulogd, установка для Debian - дистрибутивов.
apt install ulogd
В стандартных репозиториях CentOS пакета ulogd нет. Нужно использовать сторонний Использование Yum репозиторий ftp.pbone.net
# wget ftp://ftp.pbone.net/mirror/rpm.razorsedge.org/centos-5/RE-test/ulogd-1.24-2.el5.re.x86_64.rpm # rmp -i ulogd-1.24-2.el5.re.x86_64.rpm
Перепишем вышеприведенные примеры при помощи ULOG.
$IPT -A INPUT -i eth0 -m limit --limit 3/m --limit-burst 5 -j ULOG --ulog-prefix "IN_ETH0 "
- –ulog-prefix "IN_ETH0 " чтобы можно было различать статистику полученную с разных правил
После установки ulogd создает два лога:
- /var/log/ulog/ulogd.log - системный, хранит информацию о работе демона
- /var/log/ulog/syslogemu.log - лог трафика прошедшего через ULOG
- Анализ syslogemu.log. Вариант №1. Подсчитать количество попыток для каждого правила с –ulog-prefix "DROP INVALID:"
# cat syslogemu.log | grep "DROP INVALID:" | awk '{print $10}' | cut -d= -f2 | sort | uniq -c | sort -n ... 41 178.150.98.36 45 66.249.71.173 52 87.250.255.243 93 95.108.158.233 root@:/var/log/ulog#
- * Анализ syslogemu.log. Вариант №2.
root@cz5093:/var/log/ulog# cat syslogemu.log | awk '$5 == "DROP_INVALID:"' | awk '{print $9}' | cut -d= -f2 | sort | uniq -c | sort -n 1 82.144.192.104 1 95.108.214.15 1 95.108.215.14 4 178.151.96.166 4 94.179.56.223 10 62.141.67.251
Пример 1. Конфиг. файл iptables
# mkdir /home/darkfire/scripts # ln -s /home/darkfire/scripts /scripts # touch /scripts/iptables-rules.sh # chmod +x /scripts/iptables-rules.sh # nano /scripts/iptables-rules.sh #!/bin/sh IPT="/sbin/iptables" IFACE_EXT="eth0" IFACE_LOC="lo" # Flushing iptable rules. $IPT -F $IPT -t nat -F $IPT -t mangle -F $IPT -X $IPT -t nat -X $IPT -t mangle -X # Default politics $IPT -P INPUT DROP $IPT -P FORWARD DROP $IPT -P OUTPUT ACCEPT # Loopback interface $IPT -A INPUT -i $IFACE_LOC -j ACCEPT # SSH $IPT -A INPUT -p tcp -m tcp -i $IFACE_EXT --dport 22 -j ACCEPT # ICMP: разрешить все $IPT -A INPUT -p icmp -i $IFACE_EXT -j ACCEPT # SNMP: разрешить запросы с IP 10.10.10.226 $IPT -A INPUT -p udp -m udp -s 10.10.10.226 --dport 161 -j ACCEPT # Это правило обязательно если INPUT DROP. # Разрешаем прохождение statefull-пакетов. Эта цепочка обязательная в любых настройках iptables, # она разрешает прохождение пакетов в уже установленных # соединениях(ESTABLISHED), и на установление новых соединений от уже установленных (RELATED). $IPT -A INPUT -i $IFACE_EXT -m state --state ESTABLISHED,RELATED -j ACCEPT # allow nginx iptables -A INPUT -p tcp -m multiport --destination-port 80,443 -j ACCEPT # протколирование последнего правила в этом примере -P INPUT DROP $IPT -A INPUT -j LOG --log-level INFO --log-prefix "-P INPUT DROP: " # for Debian /sbin/iptables-save > /scripts/rules # for RedHat #/sbin/service iptables save #/sbin/service iptables restart
Пример 2. REJECT вместо DROP
Все новые входящие соединения, не обработанные предыдущими цепочками, записываем в лог файл и запрещаем. Эти правила оптимальнее, чем использование DROP.
# log $IPT -A INPUT -i $ISP_Gat -m limit --limit 3/m --limit-burst 5 -j ULOG --ulog-prefix "IN_Gat: " $IPT -A INPUT -p tcp -j REJECT --reject-with tcp-reset $IPT -A INPUT -p udp -j REJECT --reject-with icmp-port-unreachable $IPT -A INPUT -j REJECT --reject-with icmp-proto-unreach
Пример 3. iptables CentOS OpenVZ
- iptables.sh
#!/bin/sh IPT="/sbin/iptables" IFACE_EXT="eth0" IFACE_LOC="lo" # Flushing iptable rules. $IPT -F $IPT -t nat -F $IPT -t mangle -F $IPT -X $IPT -t nat -X $IPT -t mangle -X # Default politics $IPT -P INPUT DROP $IPT -P FORWARD DROP $IPT -P OUTPUT ACCEPT # INPUT # allow local, internal and already established connections $IPT -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT $IPT -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT #$IPT -A OUTPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT $IPT -A INPUT -i $IFACE_LOC -j ACCEPT # Ping allow $IPT -A INPUT -p icmp -j ACCEPT # SSH allow $IPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT # The rest deny $IPT -A INPUT -p tcp -j REJECT --reject-with tcp-reset $IPT -A INPUT -p udp -j REJECT --reject-with icmp-port-unreachable $IPT -A INPUT -j REJECT --reject-with icmp-proto-unreach # FORWARD $IPT -A FORWARD -s 10.161.85.101/32 -j ACCEPT $IPT -A FORWARD -d 10.161.85.101/32 -j ACCEPT $IPT -A FORWARD -s 10.161.85.102/32 -j ACCEPT $IPT -A FORWARD -d 10.161.85.102/32 -j ACCEPT $IPT -A FORWARD -j REJECT --reject-with icmp-host-prohibited # POSTROUTING $IPT -t nat -A POSTROUTING -s 10.161.85.101/24 -o eth0 -j MASQUERADE # for RedHat /sbin/service iptables save /sbin/service iptables restart
Пример 4. User defined chains. Пользовательские цепочки.
Одна из мощных возможностей iptables - это возможность создавать пользовательские цепочки (user defined chains), в дополнение к встроенным (INPUT, FORWARD и OUTPUT). По общему согласию, пользовательские цепочки всегда создаются в малом регистре. Для создания пользовательских цепочек служит команда -N, для переименования - -E, для удаления - -X. Просмотр цепочки: iptables -nL forward-ports.
Пример. Создадим правило, которая все обращения к портам от 22 до 80 включительно, проходящие через наш шлюз, будет перенаправлять в нашу цепочку forward-ports. В цепочке forward-ports будут указаны IP, обращение к которым по этим портам запрещено.
# User defined chain. forward-ports # Создание цепочки $IPT -N forward-ports # Создание правила по умолчанию $IPT -A forward-ports -j RETURN # Заполнение правилами пользовательской цепочки $IPT -I forward-ports 1 -d xxx.xxx.xxx.xxx -m comment --comment "unused" -j DROP $IPT -I forward-ports 1 -d xxx.xxx.xxx.xxx -m comment --comment "KVM vm" -j DROP $IPT -I forward-ports 1 -d xxx.xxx.xxx.xxx -m comment --comment "unused" -j DROP # правило переправления из цепочки FORWARD в нашу созданную цепочку forward-ports $IPT -I FORWARD -p tcp -m multiport --dports 22:80 -j forward-ports
Скрипт для очистки правил iptables
Скрипт для полной очистки правил Руководство по iptables: Настройка и оптимизация фаервола Linux. Правила Netfilter устанавливаются в режим разрешить все на вход и выход этого компьютера, например для того чтобы не заблокировало Использование ssh, ssh-keygen, sshpass с примерами.
- cleariptable
#!/bin/sh # iptables -F iptables -t nat -F iptables -t mangle -F iptables -X iptables -t nat -X iptables -t mangle -X # IPv6 #ip6tables --flush # Flush all IPv6 rules. ip6tables -F # default ACCEPT for ssh iptables -P INPUT ACCEPT iptables -P OUTPUT ACCEPT iptables -P FORWARD ACCEPT
Пример 5. Как перенаправить пакет с IP:PORT на localhost:PORT
Например у вас MySQL настроен стандартно на localhost порт 3306, но тут появляется программист и говорит хочу программировать нужен удаленный доступ к Mysql, да не абы как, а по порту другому 6607. Как же ему отказать? Надо делать.
iptables -t nat -I PREROUTING -p tcp -d $внешний_IP/24 --dport 6607 -j DNAT --to-destination 127.0.0.1:3306
Включаем NAT, не забудьте заменить eth0 на имя своего внешнего интерфейса
sysctl -w net.ipv4.conf.eth0.route_localnet=1
Пример 6. Настройка IPv6-файрвола (ip6tables)
Поскольку при использовании IPv6 каждый из компьютеров вашей локальной сети будет иметь белый маршрутизируемый IP-адрес, важно настроить сетевой экран, который будет блокировать входящие соединения из Интернета, но при этом разрешать исходящие из локальной сети.
sudo ip6tables -A INPUT -i lo -j ACCEPT sudo ip6tables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT sudo ip6tables -A INPUT -p icmp -j ACCEPT sudo ip6tables -A INPUT -p tcp --dport ssh -j ACCEPT sudo ip6tables -A INPUT -p tcp --dport http -j ACCEPT sudo ip6tables -A INPUT -p tcp --dport https -j ACCEPT sudo ip6tables -A INPUT -j DROP
Просмотр конфигурации IPv6
ip6tables -L -v