Шпаргалка RegExp
- Регулярные выражения в PHP - описание функций для использования регулярных выражений в PHP.
- RegExp Perl
- RegExp VoIP платформа MVTS (Мера)
- RegExp JavaScript: Справочник JavaScript Object RegExp
Регулярные выражения (regular expressions, сокр. RegExp, RegEx) — это формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов (wildcard characters). По сути это строка-шаблон (pattern), состоящая из символов и метасимволов и задающая правило поиска.
При реализации механизмов регулярных выражений обычно используются две базовые технологии: НКА (недетерминированный конечный автомат) и ДКА (детерминированный конечный автомат). Механизмы отличаются подходом к сравнению регулярного выражений со строкой. Говорят, что механизм НКА «управляется регулярным выражением», а механизм ДКА «управляется текстом». Самым распространенным является НКА.
- Программы использующие НКА: Perl, PHP, библиотека PCRE библиотека регулярных выражений, .NET, Python, JavaScript: основы, возможности и применение.
- Программы использующие ДКА: AWK примеры использования, flex, lex, Движок БД MySQL. Нет минимальных квантификаторов. ДКА стремится к максимальному захвату.
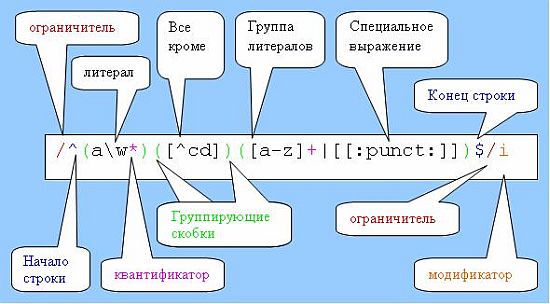
Метасимволы
| Таблица метасимволов | ||
|---|---|---|
| Элементы обозначающие отдельный символ | ||
| Метасимвол | Название | Интерпретация |
. | Точка | Один любой символ (в некоторых реализациях исключая символ новой строки). Выражение a.c соответствует строкам "abc", "a1c" и "a-c". |
[…] | Символьный класс | Любой из перечисленных символов. Используя тире можно указать диапазон символов, например, [a-f] - то же самое, что [abcdef] |
[^…] | Инвертированный символьный класс | Любой символ, не перечисленный в классе. |
| \символ | Экранирование | Если перед метасимволом ставится экранирующий префикс \, то символ интерпретируется как соответствующий литерал. Например, символ "." является спецсимволом, если же нужно чтобы он воспринимался буквально, т.е. означал именно точку, то нужно записать так: "\." |
| Квантификаторы | ||
? | Вопросительный знак | Минимальные квантификаторы. Допускается один экземпляр (ни один не требуется). Повторение предшествующего элемента ноль или один раз. Эквивалентно {0,1} |
* | Звездочка | Жадный квантификатор. Допускается любое количество экземпляров (ни один не требуется). Повторение предшествующего элемента (включая цифры, буквы или выражения) ноль или более раз. Эквивалентно {0,} Например: [0-9]* означает любое количество цифр от 0 до 9. Выражение .* означает любое количество любых символов. |
+ | Плюс | Требуется один экземпляр, допускается любое количество экземпляров. Повторение предшествующего элемента один или более раз. Эквивалентно {1,} |
{min,max}
| Интервальный квантификатор, Фигурные скобки | Требуется min экземпляров, допускается max экземпляров. Варианты записи: {n} повторение предшествующего элемента n раз (n - положительное целое число). {n,} повторение предшествующего элемента n или более раз. {n,m} повторение предшествующего элемента от n до m раз. Фигурные скобки кроме случая интервального квантификатора - являются обычными литералами. |
| Позиционные метасимволы | ||
^ | Крышка, домик, циркумфлекс | Позиция в начале строки. Если установлен флаг многострочного поиска, то начало любой строки в тексте. |
\A | Позиция в начале строки. Метасимвол \A (если он поддерживается) совпадает только в начале текста независимо от режима поиска. | |
$ | Знак доллара | Позиция в конце строки. Если установлен флаг многострочного поиска, то конец любой строки в тексте. |
\Z \z | Позиция в конце строки. Метасимвол \Z (если он поддерживается) обычно соответствует метасимволу $ в стандартном режиме, что часто означает совпадение в конце текста или перед символом новой строки, завершающим текст. Парный метасимвол \z совпадает только в конце строки без учета возможных символов новой строки. | |
\< или \b | Граница слова | Позиция в начале слова. \b граница слова, т. е. позиция между словом и пробелом или переводом строки. |
/> или \b | Граница слова | Позиция в конце слова. \b граница слова, т. е. позиция между словом и пробелом или переводом строки. |
\b | Забой | Обычно соответствует ASCII символу <BS>, код 010 (в восьмеричной системе). Обратите внимание: во многих диалектах \b интерпретируется как символ забоя только внутри символьных классов, а за их пределами – как граница слова. Во многих реализация \b только для латинских слов и Unicode не понимает. |
\B | Граница слова | Любая позиция кроме границы слова. |
| Прочие метасимволы | ||
| | Конструкция выбора | Любое из перечисленных выражений. Например, условие "или" (a или b). Так как в данном случае с обеих сторон разделителя ровно по одному символу, то можно заменить на [ab] |
(…) | Круглые скобки | Служит для ограничения конструкции выбора, группировки для применения квантификаторов и «сохранения» текста для обратных ссылок. Подвыражения нумеруются в соответствии с номером по порядку открывающей круглой скобки, начиная с 1. Подвыражения могут быть вложенными – например, (Washington(•DC)?). Обычные (сохраняющие) круглые скобки (…) могут быть применены только с целью группировки, но и в этом случае соответствующая специальная переменная заполняется текстом совпадения. |
(?:…) | Круглые скобки | Служит для группировки символов без сохранения. Т.е. нельзя использовать обратные ссылки для выражения в таких скобках. |
\1,\2,… | Обратная ссылка | Текст, ранее совпавший с первой, второй и т.д. парами круглых скобок. |
| Метасимволы для представления машиннозависимых управляющих символов | ||
\a | Сигнал | Сигнал (при «выводе» раздается звуковой сигнал). Обычно соответствует ASCII символу <BEL>, код 007 (в восьмеричной системе). |
\e | Символ Escape | Обычно соответствует ASCII символу <ESC>, код 033 (в восьмеричной системе). |
\f | Перевод формата | Обычно соответствует ASCII символу <FF>, код 014 (в восьмеричной системе). |
\n | Символ перевода строки | Новая строка. На большинстве платформ (включая Unix и DOS/Windows) обычно соответствует ASCII символу <LF>, код 012 (в восьмеричной системе). В системе MacOS обычно соответствует ASCII символу <CR>, код 015 (в восьмеричной системе). В Java и языках .NET всегда соответствует ASCII символу <LF> независимо от платформы. |
\r | Символ возврата каретки | Обычно соответствует ASCII символу <CR>. В системе MacOS обычно соответствует ASCII символу <LF>. В Java и языках .NET всегда соответствует ASCII символу <CR> независимо от платформы. |
\t | Символ горизонтальной табуляции | Горизонтальная табуляция. Обычно соответствует ASCII символу <НТ>, код 011 (в восьмеричной системе). |
\v | Символ вертикальной табуляции | Вертикальная табуляция. Обычно соответствует ASCII символу <VT>, код 013 (в восьмеричной системе). |
| Прочие метасимволы 2 | ||
\s | соответствует любому «пробельному» символу (пробел, табуляция, новая строка, перевод формата и т. д.). | |
\S | Любой символ, кроме пробельных. Все, что не относится к \s | |
\w | Цифра, буква (латинский алфавит) или знак подчеркивания. Эквивалентно [0-9a-zA-Z_]. Частая конструкция для поиска слов \w+ | |
\W | Любой символ, кроме цифр, букв (латинский алфавит) и знака подчеркивания. Все, что не относится к \w. Эквивалентно[^0-9a-zA-Z_] |
|
\d | Цифра. Эквивалентно [0-9] | |
\D | Любой символ, кроме цифр. Все, что не относится к \d Эквивалентно [^0-9] |
|
Максимализм квантификатора *
Регулярное выражение .* всегда распространяет совпадение до конца строки. Это связано с тем, что .* стремится захватить все, что может. Впрочем, позднее часть захваченного может быть возвращена, если это необходимо для общего совпадения. Иногда это поведение вызывает немало проблем. Рассмотрим регулярное выражение для поиска текста, заключенного в кавычки. На первый взгляд напрашивается простое ".*", но попробуйте на основании того, что нам известно о .*, предположить, какое совпадение будет найдено в строке:
The name "McDonald's" is said "makudonarudo" in Japanese
После совпадения первого символа " управление передается конструкции .*, которая немедленно захватывает все символы до конца строки. Она начинает нехотя отступать (под нажимом механизма регулярных выражений), но только до тех пор, пока не будет найдено совпадение для последней кавычки. Если прокрутить происходящее в голове, вы поймете, что найденное совпадение будет выглядеть так(выделено нижним подчеркиванием):
The name "McDonald's" is said "makudonarudo" in Japanese
Найден совсем не тот текст, который мы искали. Это одна из причин, по которым не стоит злоупотреблять .*, – если не учитывать проблем максимального совпадения, эта конструкция часто приводит к неожиданным результатам. Как же ограничить совпадение строкой "McDonald's"? Главное – понять, что между кавычками должно находиться не «все, что угодно», а «все, что угодно, кроме кавычек». Если вместо .* воспользоваться выражением [^"]*, совпадение не пройдет дальше закрывающей кавычки.
При поиске совпадения для "[^"]*" механизм ведет себя практически так же. После совпадения первой кавычки [^"]* стремится захватить как можно большее потенциальное совпадение. В данном случае это совпадение распространяется до кавычки, следующей после McDonald's. На этом месте поиск прекращается, поскольку [^"] не совпадает с кавычкой, после чего управление передается закрывающей кавычке в регулярном выражении. Она благополучно совпадает, обеспечивая общее совпадение:
The name "McDonald's" is said "makudonarudo" in Japanese
Минимальные квантификаторы *?
В некоторых вариантах НКА поддерживаются минимальные квантификаторы, при этом *? является минимальным аналогом квантификатора *. Квантификатор стремится к минимальному захвату.
Завершители строк Unicode
В Unicode определяется несколько символов (а также одна последовательность из двух символов), которые считаются завершителями строк (line terminators).
| Завершители строк в Юникоде | |
|---|---|
| Символ | Описание |
| LF U+000A | Перевод строки (ASCII: Расшифровка аббревиатуры, история и применение) |
| VT U+000B | Вертикальная табуляция (ASCII) |
| FF U+000C | Перевод формата (ASCII) |
| CR U+000D | Возврат каретки (ASCII) |
| CR/LF U+000D U+000A | Возврат каретки/перевод строки (ASCII последовательность) |
| NEL | Следующая строка (Юникод) |
| LS U+2028 | Разделитель строк (Юникод) |
| PS U+2029 | Разделитель абзацев (Юникод) |
При наличии полноценной поддержки со стороны программы завершители строк влияют на результаты чтения строк из файла (в сценарных языках – включая файл, из которого читается программа). В регулярных выражениях они могут влиять как на то, какие символы совпадают с ., так и на возможность совпадения метасимволов ^, $ и \Z
Опережающие, ретроспективные проверки
- Опережающая проверка (?=…), (?!…) - анализирует текст, расположенный справа и проверяет возможность совпадения выражения.
- Ретроспективная проверка (?⇐…), (?<!…) - текст анализируется к левому краю.
Примеры использования:
Unicode. Алфавиты и блоки: \р, \Р
- Подробно тема раскрыта в книге Джеффри Фридл - "Регулярные выражения" 3-е издание Глава 3. стр. 159
Свойства Unicode, алфавиты и блоки: \р{свойство}, \Р{свойство}. На концептуальном уровне Юникод представляет собой отображение множества символов на множество кодов, но стандарт Юникода не сводится к простому перечислению пар. Он также определяет атрибуты символов (например, «этот символ является строчной буквой», «этот символ пишется справа налево», «этот символ является диакритическим знаком, который должен объединяться с другим символом» и т. д.). Уровень поддержки этих атрибутов зависит от конкретной программы, но многие программы с поддержкой Юникода позволяют находить хотя бы некоторые из них при помощи конструкций \p{атрибут} (символ, обладающий указанным атрибутом) и \P{атрибут} (символ, не обладающий атрибутом).
Оптимизация RegExp
Рекомендации по оптимизации регулярных выражений.
- Ускоренное достижение совпадения. Руководствуясь знаниями принципов работы традиционного механизма НКА, можно привести механизм к совпадению по ускоренному пути. Рассмотрим пример this|that. Каждая альтернатива начинается с th, если у первой альтернативы не найдется совпадение для th, то th второй альтернативы тоже заведомо не совпадет, поэтому такая попытка заведомо завершится неудачей. Чтобы время не тратилось даром, можно сформулировать то же выражение в виде th(?:is|at). В этом случае th проверяется всего один раз, а относительно затратная конструкция выбора откладывается до момента, когда она становится действительно необходимой. Кроме того, в выражении th(?:is|at) проявляется начальный литерал th, что позволяет задействовать ряд других оптимизаций.
- Привязка к началу текста/логической строки. Эта разновидность оптимизации понимает, что регулярные выражения, начинающиеся с ^, могут совпасть только от начала строки, поэтому их не следует применять с других позиций.
- Привязка к концу текста/логической строки. Эта разновидность оптимизации основана на том, что совпадения некоторых регулярных выражений, завершающихся метасимволом $ или другими якорями конца строки, должны отделяться от конца строки определенным количеством байтов. Например, для выражения regex(es)?$ совпадение должно начинаться не более чем за восемь символов от конца строки, поэтому механизм может сразу перейти к этой позиции. При большой длине целевого текста это существенно сокращает количество начальных позиций поиска. Восемь, а не семь, потому что во многих диалектах $ может совпадать перед завершающим символом новой строки.
- Исключение по первому символу/классу/подстроке. Данный вид оптимизации руководствуется информацией (любое совпадение должно начинаться с конкретного символа или подстроки), на основании которой производится быстрая проверка и применение регулярного выражения только с соответствующих позиций строки. Например, выражение this|that|other может совпадать только в позициях, начинающихся с [ot]; механизм проверяет все символы строки и применяет выражение только с соответствующих позиций, что может привести к огромной экономии времени. Чем длиннее проверяемая строка, тем меньше вероятность ложной идентификации начальных позиций.
- Используйте несохраняющие круглые скобки. Если вы не используете текст, совпадающий с подвыражениями в круглых скобках, используйте несохраняющие скобки (?:…). Помимо прямого выигрыша из-за отсутствия затрат на сохранение появляется побочная экономия – состояния, используемые при возврате, становятся менее сложными и поэтому быстрее восстанавливаются.
Примеры
Разбить число на разряды
Задача: Разбить число на разряды например запятыми. Формально задача выглядит так «вставить запятые во всех позициях, у которых количество цифр справа кратно трем, а слева есть хотя бы одна цифра»
Второе требование выполняется при помощи ретроспективной проверки. Одной цифры слева достаточно для выполнения этого требования, а этот критерий задается выражением (?⇐\d).
Группа из трех цифр определяется выражением \d\d\d. Заключим ее в конструкцию (…)+, чтобы совпадение могло состоять из нескольких групп, и завершим метасимволом $, чтобы гарантировать отсутствие символов после совпадения. Само по себе выражение (\d\d\d)+$ совпадает с группами из трех цифр, следующими до конца строки, но в конструкции опережающей проверки (?=…) оно совпадает с позицией, справа от которой до конца строки следуют группы из трех цифр. Однако перед первой цифрой запятая не ставится, поэтому совпадение дополнительно ограничивается ретроспективной проверкой (?⇐\d).
Чтобы выражение стало более эффективным можно добавить несохраняющие скобки ?: в (?:\d\d\d), в этом случае подсистема регулярных выражений не будет тратить ресурсы на сохранение текста в круглых скобках.
- Реализация PHP (PCRE библиотека регулярных выражений):
<?php $n = "7500400300222"; //$n = preg_replace('/(?<=\d)(?=(\d\d\d)+$)/', ',', $n); $n = preg_replace('/(?<=\d)(?=(?:\d\d\d)+$)/', ',', $n); echo "$n\n"; ?>
Ссылки
- Джеффри Фридл - "Регулярные выражения" 3-е издание ISBN-13: 978-5-93286-121-9 ISBN-10: 5-93286-121-5



📌 Удобный подбор VPS по параметрам доступен на DIEGfinder.com - официальном инструменте проекта DIEG. Это часть единой экосистемы, созданной для того, чтобы помочь быстро найти подходящий VPS/VDS сервер для любых задач хостинга.

📌 Для тестирования скриптов, установщиков VPN и Python-ботов рекомендуем использовать надежные VPS на короткий срок. Подробнее о быстрой аренде VPS для экспериментов - читайте здесь.
💥 Подпишись в Телеграм 💥 и задай вопрос по сайтам и хостингам бесплатно!